贡献指南 —— 如何实现 nature 编程语言
源码编译
nature 编译器使用纯 C 语言编写,基于 C11 规范,GCC 版本大 11。linux runtime 基于 musl libc 静态库编译。使用 cmake 作为构建工具, cmake 版本大于 3.22
当前版本发布使用的编译环境
Apple clang version 16.0.0 (clang-1600.0.26.6)
gcc version 14.2.0 (Ubuntu 14.2.0-4ubuntu2)
编译 runtime
# darwin/amd64 架构,仅支持在 darwin 设备编译
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/darwin-amd64-toolchain.cmake && cmake --build build-runtime --target runtime
# darwin/arm64 架构,仅支持在 darwin 设备编译
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/darwin-arm64-toolchain.cmake && cmake --build build-runtime --target runtime
# linux/amd64 架构,设备需要安装 x86_64-linux-musl-gcc 编译器
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-amd64-toolchain.cmake && cmake --build build-runtime --target runtime
# linux/arm64 架构,设备需要安装 aarch64-linux-musl-gcc 编译器
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-arm64-toolchain.cmake && cmake --build build-runtime --target runtime
# linux/riscv64 架构,设备需要安装 riscv64-linux-musl-gcc 编器
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-riscv64-toolchain.cmake && cmake --build build-runtime --target runtime编译 runtime 会生成 libruntime.a 自动放入到 lib 目录的对应架构中,如 nature/lib/linux_arm64/libruntime.a
编译源码
源码编译依赖 libruntime.a,根据实际需要手动进行编译。
# 使用 build-release 目录作为编译目录, 如果安装了跨平台编译器,则可以通过 TOOLCHAIN_FILE 指定编译架构,如果需要静态编译同样需要设置 DCMAKE_TOOLCHAIN_FILE
# cmake -B build-release -DCMAKE_VERBOSE_MAKEFILE=ON -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-amd64-toolchain.cmake -DCMAKE_BUILD_TYPE=Release -DCPACK_OUTPUT_FILE_PREFIX=$(pwd)/release
cmake -B build-release -DCMAKE_VERBOSE_MAKEFILE=ON -DCMAKE_BUILD_TYPE=Release -DCPACK_OUTPUT_FILE_PREFIX=$(pwd)/release
# 编译 cmake --build build-release -- -j$(nproc)
cmake --build build-release
# 测试
cmake --build build-release --target test
# 安装, 默认使用 /usr/loca/nature 作为安装目录,可能需要增加 sudo 权限
cmake --build build-release --target install
# 打包,生成的压缩包在 release 目录
cmake --build build-release --target package编码规范
文件命名
- 源文件使用小写字母,以 .c 结尾
- 头文件使用小写字母,以 .h 结尾
- 文件名应当简洁且能表达模块功能
函数命名
- 使用小写字母和下划线组合
- 使用模块名作为函数前缀,避免冲突
- 不对外的函数可以直接使用 static 前缀在 c 文件内部声明
类型命名
- 结构体类型以 _t 结尾
- 使用 typedef 定义类型
typedef struct module_t {...} module_t;
typedef struct coroutine_t {...} coroutine_t;变量命名
- 使用小写字母和下划线
- 变量名应当清晰表达其用途
- 临时变量可以使用简短名称
代码格式化
基于项目根目录下的 .clang-format 进行代码格式化
注释规范
简单模块/函数可以不进行注释,复杂模块/函数需要注释说明清晰,尽量采用英文注释。目前源码中的中文注释后续都会改成英文注释。
测试说明
测试文件统一放在 tests 目录下,其中源码测试放在 tests/features 目录下,测试基于 CMake Ctest 实现
tests/features 中有三种类型的源码测试方式,自行参考 tests 目录中的用例
- 目录
- 单文件
- testar 测试压缩文件
Git 分支管理
nature 相关仓库都采用 Github Flow 作为工作流程。
既 master 分支总是保持最新的经过测试的代码,相关的 feature/bug fixed 都基于 master checkout, 开发完成后 PR 到 master 并删除功能分支。
如何贡献代码?
nature 编程语言使用 github 作为主代码仓库,目前没有委员会等机构。 开发决定、PR 合并、Review、Release 由项目发起人 weiwenhao 负责。
Feature/Refactor/Std Library/复杂 Bug Fixed 类型的代码贡献需要先在 Github Issue 或者邮件中提出想法并进行讨论,讨论通过后,再进行开发提交 PR。简单的 Bug Fixed 可以直接提交 PR。
Feature/Std Library/Bug Fixed 开发完成后需要添加测试用例进行测试,当前功能测试完成后,需要在本地进行 CMake CTest 回归测试后再提交 PR。
DeepWiki
https://deepwiki.com/nature-lang/nature 参考 deepwiki 和后续的章节以了解 nature 的源码结构和运行流程
目录结构
├── CMakeLists.txt # 项目主构建配置文件
├── LICENSE-APACHE # Apache 开源协议
├── LICENSE-MIT # MIT 开源协议
├── README.md # 英文说明文档
├── README_CN.md # 中文说明文档
├── VERSION # 版本信息文件
├── cmake # cmake 工具链和构建配置目录
├── cmd # 命令行工具相关代码
├── config # 编译器配置文件目录
├── include # 第三方库头文件目录
│ ├── mach # MacOS 系统调用相关头文件
│ ├── mach-o # MacOS 可执行文件格式相关头文件
│ ├── uv # libuv 异步 IO 库头文件
│ ├── uv.h
│ └── yaml.h # yaml 解析库头文件
├── lib # 编译产物和依赖库目录
│ ├── darwin_amd64 # MacOS x86_64 架构库文件
│ ├── darwin_arm64 # MacOS ARM 架构库文件
│ ├── linux_amd64 # Linux x86_64 架构库文件
│ └── linux_arm64 # Linux ARM 架构库文件
├── main.c # 程序入口文件
├── nls # 国际化资源文件目录
├── package # 打包相关配置和脚本
├── runtime
│ ├── CMakeLists.txt # 运行时库构建配置
│ ├── nutils # user code 依赖的如 vec/map/set 等帮助函数
│ ├── runtime.h # 运行时起点
├── src
│ ├── binary # 汇编器和链接器源码
│ ├── build # 编译器构建入口
│ ├── lower # IR 降级优化相关代码
│ ├── native # 目标平台代码生成
│ ├── register # 寄存器分配相关代码
│ ├── semantic # 语义分析相关代码
│ ├── symbol # 符号表相关代码
│ ├── syntax # 语法分析相关代码
│ ├── ast.h # 抽象语法树定义
│ ├── cfg.h # 控制流图定义
│ ├── debug # 调试信息相关代码
│ ├── error.h # 错误处理定义
│ ├── linear.h # AST to LIR 编译逻辑
│ ├── lir.h # 低级 IR 定义
│ ├── module.h # nature 按模块进行编译, 这是模块相关类型定义
│ ├── package.h # 包管理定义
│ ├── ssa.h # SSA 形式定义
│ └── types.h # 基础类型定义
├── std # 标准库源码
├── tests # 测试相关文件
│ ├── CMakeLists.txt # 测试构建配置
│ ├── features # 功能测试用例
│ ├── test.h # 测试框架头文件
│ ├── test_arm64_encoding.c # ARM64 编码测试
│ ├── test_bitmap.c # 位图测试
│ ├── test_hello.c # Hello World 示例测试
└── utils # 通用工具库
├── autobuf.h # 自动扩容缓冲区
├── bitmap.h # 位图操作
├── ct_list.h # 动态数组
├── custom_links.h # 自定义链接数据,runtime/compiler 都依赖
├── error.h # 错误处理
├── exec.h # 测试进程执行
├── helper.h # 常用辅助函数
├── linked.h # 链表操作
├── log.h # compiler 日志
├── mutex.h # 互斥锁
├── sc_map.h # 哈希表实现
├── slice.h # 动态指针数组
├── stack.h # 栈数据结构
├── string_view.h # 字符串视图
├── table.h # hash 表(废弃,请使用 sc_map 替代)
├── toml.h # TOML 配置解析
├── type.h # runtime/compiler 共同依赖的 nature 类型定义和反射类型实现
└── ymal # YAML 解析相关编译流程
nature 的 lsp 使用 rust 编程语言实现,其有和 nature compiler 一样的前端逻辑实现,如果你更熟悉 rust 可以直接参考 nature lsp 源码。
编译器前端
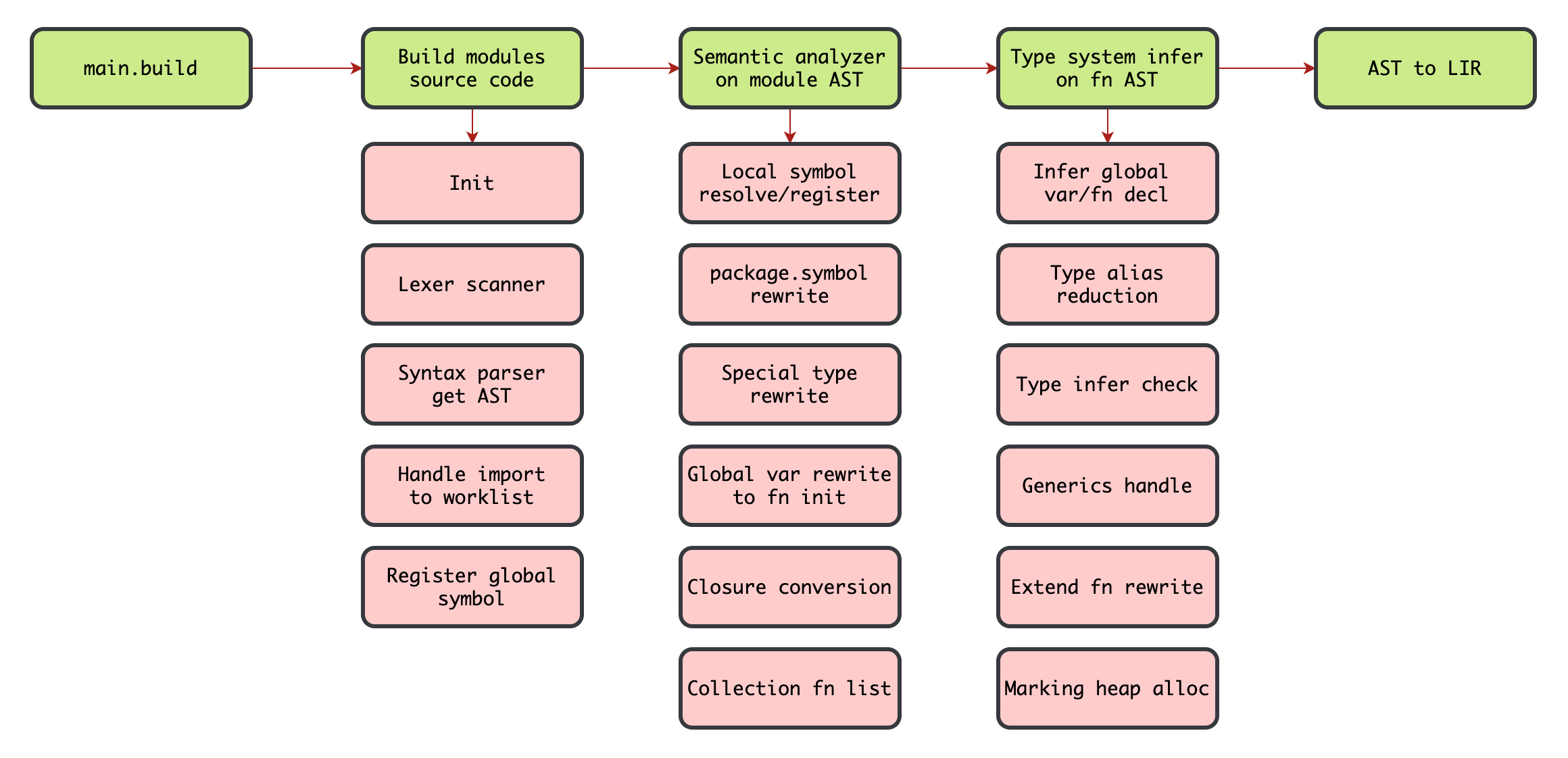
编译器后端
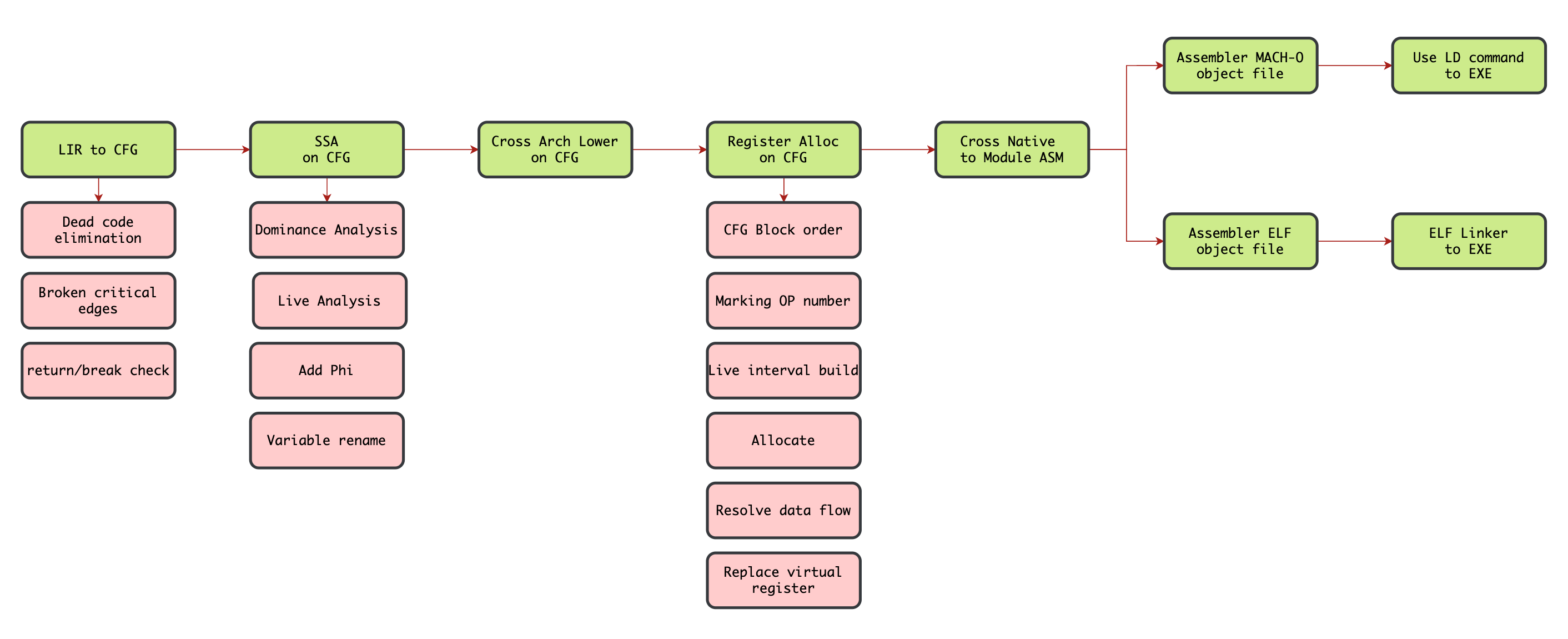
相关代码位置
- main.build -> src/build/build.c#build 入口
- Build modules -> src/build/build.c#build_modules
- Semantic analyzer -> src/semantic/analyzer.c#analyzer
- Type system infer -> src/semantic/infer.c#pre_infer and infer
- AST to LIR -> src/linear.c#linear
- LIR to CFG -> src/cfg.c#cfg
- SSA on CFG -> src/ssa.c#ssa
- Cross Arch Lower -> src/lower
- Register Alloc -> src/register/linearscan.c#reg_alloc
- Cross Native -> src/native
- Assembler file -> src/build/build.c#build_assembler
- Elf Linker -> src/build/build.c#build_elf_exe -> src/binary/elf/linker.c#elf_exe_file_format
- Mach-O LD -> src/build/build.c#build_mach_exe
运行流程
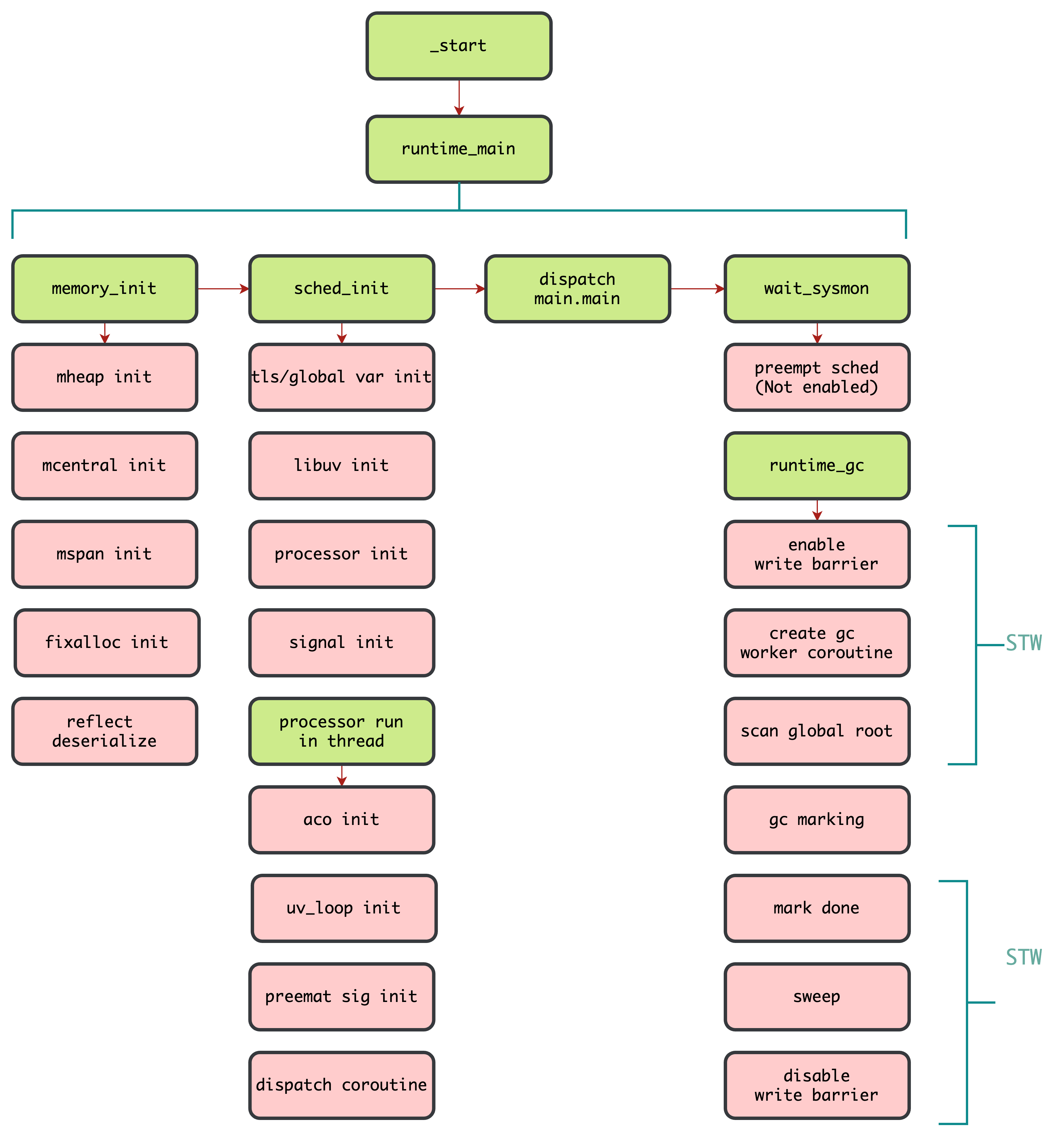
相关代码位置
- runtime_main -> runtime/runtime.c#runtime_main
- sched_init -> runtime/processor.c#sched_init
- processor_run -> runtime/processor.c#processor_run
- wait_sysmon -> runtime/sysmon.c#wait_sysmon
- runtime_gc -> runtime/collector.c#runtime_gc
Lexer Scanner
src/syntax/scanner.c
这是一个词法分析器(Scanner),主要负责将源代码文本转换成 token 序列。Lexer Scanner 是编译器前端的第一个阶段,为后续的语法分析提供基础。
Syntax Parser
src/syntax/parser.c
这是一个语法解析器(Syntax Parser)的实现文件,主要负责将词法分析器(Lexer Scanner)生成的 token 序列转换成抽象语法树(AST)。该解析器采用递归下降(Recursive Descent)的方式实现,是编译器前端的核心组件之一。
表达式解析采用运算符 Precedence Climbing 算法,通过 parser_expr() 和 parser_precedence_expr() 实现,parser_expr 包含了几个特殊的 expr, 如 go/match/fndef/struct_new
使用 PARSER_ASSERTF 进行错误检查和报错,目前编译器还没有实现错误恢复机制,lsp 已经实现了相关的错误恢复机制,能够继续向后解析。
有歧义的符号会进行 lookhead 解析确定语意。
Semantic Analyzer
src/semantic/analyzer.c
这是编译器中的语义分析器(Semantic Analyzer)实现,主要负责:
- 符号解析和作用域分析
- 变量和函数的唯一标识符生成
- 闭包变量捕获处理
- 模块导入和符号可见性分析
- 类型别名解析
- 全局变量初始化
- 使用 ANALYZER_ASSERTF 宏进行错误检查和报告
- 将 module 维度的 AST 转换到 fn 维度,后续的流程都在 fn 维度进行
Type System Infer
src/semantic/infer.c
这是编译器中的类型推导(Type Inference)模块,主要负责
- 类型推导和检查
- 变量声明的类型推导
- 表达式类型推导和检查
- 函数调用参数类型检查
- 泛型类型特化和实例化
- 类型还原(Type Reduction)
- 将类型别名(Type Alias)还原为具体类型
- 处理复合类型(数组、指针、结构体等)的类型还原
- 泛型参数的类型还原
- 主要功能
pre_infer: 预处理 global var decl 和 fn decl 主要是处理了函数的声明,没有处理 bodyinfer: 入口函数,处理整个模块的类型推导infer_expr: 表达式类型推导reduction_type: 类型还原,以及类型参数处理infer_fndef: 函数定义的类型推导generics_special_fn: 泛型函数处理
使用 INFER_ASSERTF 宏进行类型错误检查和报告,这个模块是编译器类型系统的核心,确保程序中的类型使用正确,为后续的代码生成提供类型信息支持。它在语义分析阶段之后、代码生成之前执行,是保证类型安全的关键环节。
Linear to LIR
src/linear.c
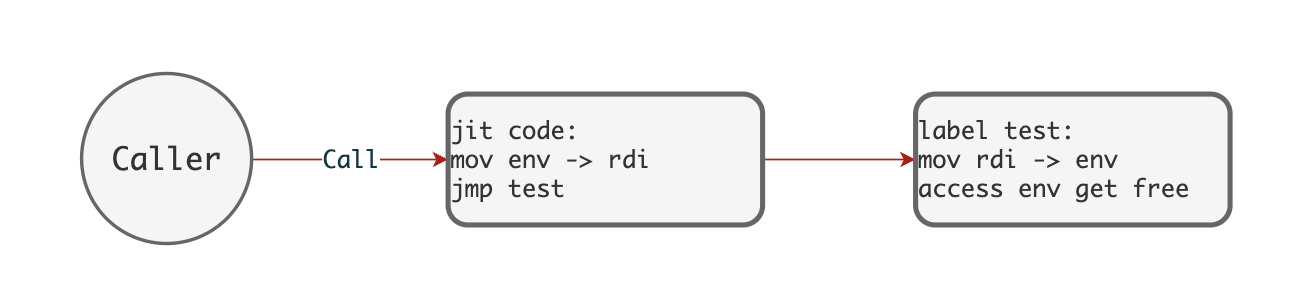
这是编译器的线性中间代码(Linear IR)生成模块,主要负责将 AST 转换为线性的中间表示代码。目前包含了大量的 runtime call 调用。后续版本中应该使用内联优化将 runtime call 转换为 LIR 实现。
闭包编译使用了基于 JIT 的方式,简化了编译流程,且调用者(Caller)不需要关心闭包的引用环境。如下图
Nature 要求变量在初始化时必须赋值,但在结构体初始化上有所宽松,会为大部分类型赋默认值:
- int 的默认值是 0
- string 的默认值是空字符串 ''
- vec/map/set 的默认值是对应的空容器
- tup/struct 会递归地为其成员赋默认值
某些类型因为无法设置合理的默认值,所以必须手动赋值,如函数类型(fn)和指针类型(ptr)。
LIR to CFG
src/cfg.c
这是编译器的控制流图(Control Flow Graph, CFG)构建模块
- 基本块构建
- 通过
cfg_build实现 - 根据标签(label)和跳转指令将线性IR代码分割成基本块
- 建立基本块之间的顺序和跳转关系
- 关键边处理
- 通过
broken_critical_edges实现 - 处理控制流图中的关键边(critical edges)
- 插入空的中间基本块,优化数据流分析,后续寄存器分配中 relosve_data_flow 不允许存在关键边
- 不可达代码消除
- 通过
cfg_pruning实现 - 删除从入口块无法到达的基本块
- 维护基本块之间的前驱和后继关系
- return check
- return 语句检查:确保所有执行路径都有返回语句
- ret 语句检查:确保 match/catch 结构中有正确的表达式退出
SSA
src/ssa.c
这个文件实现了 SSA (Static Single Assignment) 形式的代码转换,是编译器优化中的一个重要步骤。主要功能包括
-
支配关系分析
- ssa_domers : 计算每个基本块的支配者集合
- ssa_imm_domer : 计算每个基本块的直接支配者
- ssa_df : 计算支配边界
-
变量活跃分析
- ssa_use_def : 分析每个基本块中变量的使用和定义
- ssa_live : 进行活跃性分析,计算每个基本块的入口活跃变量(live_in)和出口活跃变量(live_out)
-
SSA 转换
- ssa_add_phi : 在必要的位置插入 φ 函数
- ssa_rename : 对变量进行重命名,确保每个变量只被赋值一次
SSA 形式的主要特点是每个变量只被赋值一次,这样可以
- 简化数据流分析
- 便于进行后续的代码优化
- 使得变量的定义和使用关系更加清晰
目前 nature 编译器还没有开始进行基于 SSA 形式的优化。
SSA 示例 1:
int foo = 1
foo = foo + 2
if (true) {
int car = 4
foo = 2
} else {
int car = 5
foo = 3
}
println(foo)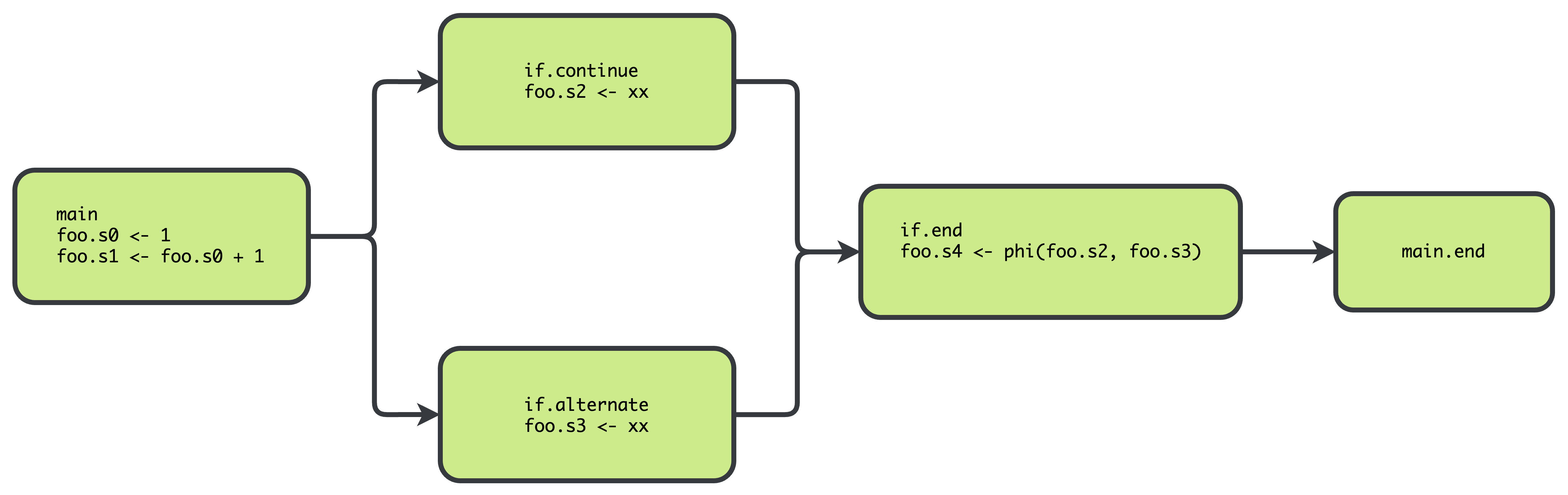
SSA 示例 2:
int foo = 0
for (int i = 0; i <= 100; i+=1) {
if ((i % 2) == 0) {
foo += i
}
}
println(foo)
Cross Lower
src/lower
lower 主要负责将 LIR 转换为 AMD64/ARM64 架构特定的指令形式,如在 AMD64 架构下,ADD 是二元指令,其中一个源操作数和目标操作数必须是同一个寄存器,又比如 idiv 使用 rdx:rax 寄存器作为被除数。
并实现了架构相关的调用约定(Calling Convention)。以 AMD64 架构为例:
- 函数调用时,参数按顺序传入指定的寄存器:第一个参数使用 rdi,第二个参数使用 rsi,以此类推
- 函数返回值统一存放在 rax 寄存器中
在进行寄存器分配之前,需要先处理这些与架构相关的物理寄存器(Fixed Register)约束。这样在后续的寄存器分配阶段,编译器就能准确地计算出每个变量(包括虚拟寄存器和物理寄存器)的生命周期,从而做出更优的分配决策。
数组参数传递的特殊处理:
C 语言中的数组作为函数参数时,会自动退化为指针,实际上传递的是数组的首地址。而在 nature 编程语言中,希望数组参数采用值传递的方式(即复制整个数组的内容)。为了实现这一点,在处理函数调用参数时(Lower Call Args)
- 在栈上分配一块与原数组大小相同的空间
- 将原数组的内容完整复制到这块栈空间中
- 将这块栈空间的地址作为参数传递给函数
这样就确保了函数内部对数组的修改不会影响到原数组,实现了真正的值传递语义。如果需要进行和 C 语言一样的数组引用传递,只需要 arr as anyptr 即可取消这种复制行为基于引用数据传递。
Register Alloc
src/register
寄存器分配是将程序中的变量映射到物理寄存器的过程,由于寄存器数量有限但访问速度快,合理的寄存器分配对程序性能影响很大。
Nature 编译器采用线性扫描算法基于 SSA 形式的 LIR 进行寄存器分配。主要参考了两篇论文
- Linear Scan Register Allocation for the Java HotSpot Client Compiler. —— Wimmer, C.
- Linear Scan Register Allocation on SSA Form,ssa —— Christian Wimmer Michael Franz
主要组件:
- interval.c : 构建变量的生命周期区间
- allocate.c : 实现核心分配算法
- register.c : 管理物理寄存器
- amd64.c/arm64.c : 不同架构的寄存器定义
工作流程:
-
interval_block_order : 基本块排序
-
linear_prehandle : 增加指令序列号
-
interval_build : 构建虚拟变量和物理寄存器的生命周期区间
-
allocate_walk : 遍历生命周期区间,分配物理寄存器,并处理寄存器溢出
-
resolve_data_flow : 处理基本块边界的数据流,并消除 PHI OP
-
replace_virtual_register : 将虚拟寄存器替换为物理寄存器
经过寄存器分配后 LIR 中不再包含虚拟的 VAR,可以方便转换为汇编代码。当前版本中由于存在大量的 runtime call 导致的寄存器溢出,所以寄存器分配的性能较差。
Cross Native
src/native
native 将寄存器分配完成后的 LIR 转换为汇编代码,汇编代码符合 AMD64/ARM64 架构的汇编语法规范和指令集。当然实际上是转换成 C 语言数组,而不会直接转换为 text。
如 list_push(operations, AMD64_ASM("mov", dst_operand, src_operand));
Assembler
src/binary/encoding/amd64/opcode.c —— amd64 汇编器 src/binary/encoding/arm64/opcode.c —— arm64 汇编器
汇编器的主要工作是将 Native 生成的汇编语法数组转换为对应 CPU 架构要求的二进制实现。
对于 AMD64 架构,通过 amd64_asm_inst_encoding 函数将汇编指令编码为机器码,这个过程会生成一个字字典树用于选择合适的 amd64 指令,指令选择完成后进行前缀、操作码、ModR/M、SIB 以及可能的位移和立即数等多个部分的数据填充,最终生成可变长度的机器码。 基于 amd64 指令集构造出的字典树示例
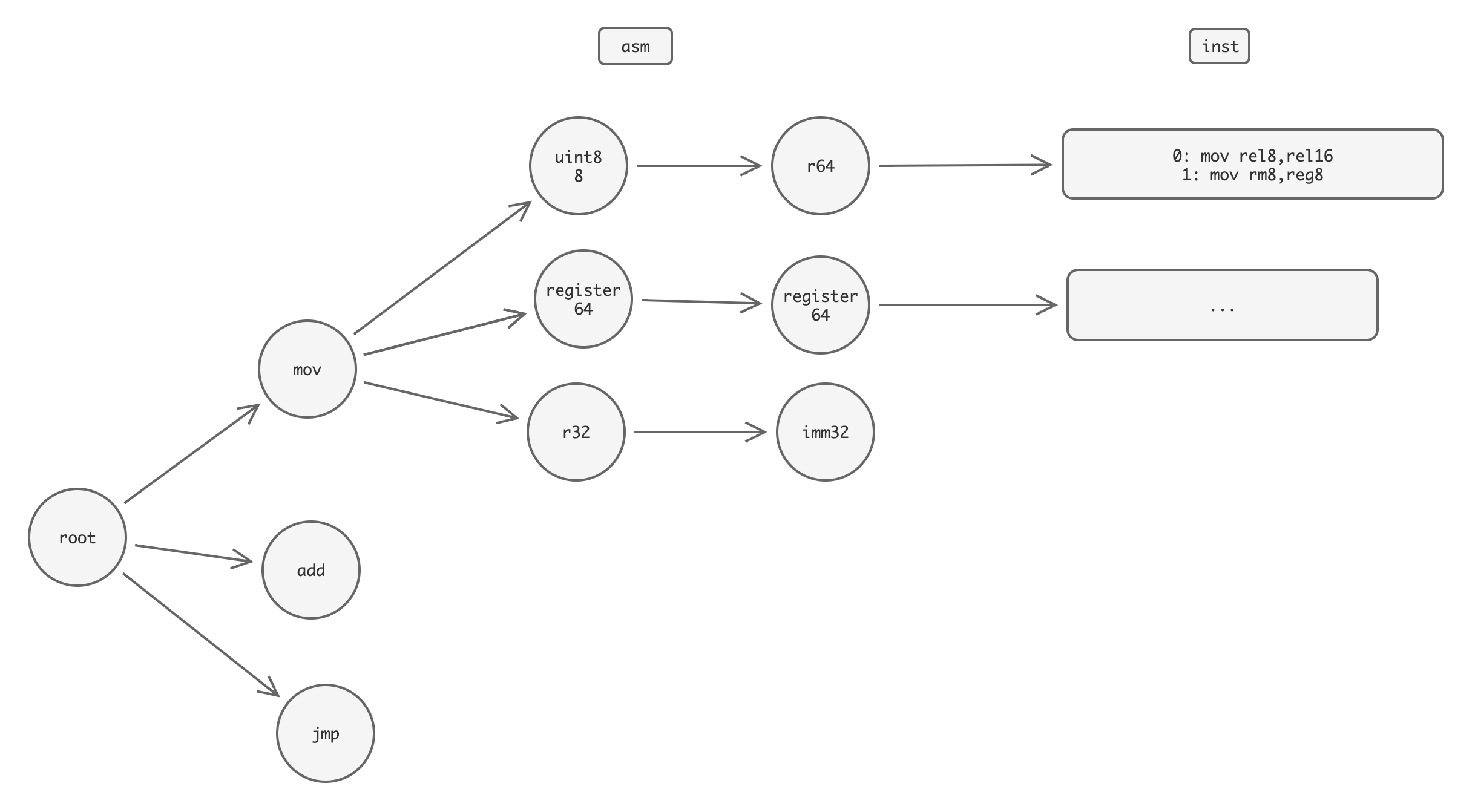
在 ARM64 架构中, arm64_asm_inst_encoding 函数则采用了更为简洁的实现方式,它会将汇编指令匹配到相应的操作码处理函数,然后生成固定 4 字节长度的机器码。
上述的汇编函数在生成操作系统相关 object 文件的时候调用。相关代码在
src/build/build.c#elf_assembler_module -> elf_amd64_operation_encodings/elf_arm64_operation_encodings
src/build/build.c#mach_assembler_module -> mach_amd64_operation_encodings/mach_arm64_operation_encodings
encodings 主要负责将汇编指令编码为机器码,并处理符号重定位问题。它通过两次遍历来完成工作:
- 第一次遍历处理汇编指令的编码和已知符号的重定位
- 第二次遍历处理第一次遍历中未能解析的符号引用
最后,将所有编码后的指令数据写入到代码段中,并记录生成的 fn label 的指令长度,为后续的反射机制做铺垫
Linker
src/binary/elf/linker.c#elf_exe_file_format —— elf 链接器实现
链接器将负责多个 object/archive 文件合并成一个可执行文件。nature 的链接器是一个简单实现,主要实现了静态链接功能,工作流程
- elf_resolve_common_symbols : 处理 COMMON 符号,将其分配到 .bss 段
- elf_build_got_entries : 构建 GOT/PLT 表项,处理动态链接相关的重定位
- set_section_sizes : 计算各段的大小
- alloc_section_names : 分配段名字符串表
- layout_sections : 布局所有段,计算段的虚拟地址和文件偏移
- elf_relocate_symbols : 重定位符号,计算符号的最终地址
- elf_relocate_sections : 处理所有重定位段
- elf_fill_got : 填充 GOT 表
- elf_output : 生成最终的 ELF 文件
不支持动态链接/版本控制/调试信息处理
Runtime Sched
runtime/processor.c#sched_init
nature 的 sched 是一个类似 golang GMP 调度模型的简单实现,是围绕着 Processor + Coroutine 的调度模型实现。
核心组件
- n_processor_t :处理器结构体,代表一个执行单元
- coroutine_t :协程结构体,代表一个可执行的任务
- 共享处理器列表(share_processor_list)和独占处理器列表(solo_processor_list)
主要功能
- 协程调度:创建、运行、切换和销毁协程
- 处理器管理:创建和管理多个处理器实例
- 非抢占式调度:通过 safepoint 进行 yield
- GC 相关:支持垃圾回收的安全点(STW)机制
关键函数
- sched_init() :调度器初始化
- processor_run() :处理器主循环
- coroutine_resume() :恢复协程执行
- rt_coroutine_dispatch() :协程调度分配
Tips
- 基于 safepoint 进行协作式 yield,safepoint 插入在函数结尾和函数调用之前,所以如果遇到长时间 for 循环且没有函数调用时会导致其他协程无法正常调度,且无法进行 GC
- nature 目前基本没有实现协程调度器,协程创建完成后就会均衡的固定在 Processor 中
- nature 的协程使用共享栈协程实现,所以 nature 拥有更加轻量的协程栈,以及创建速度和切换速度。协程共享栈示意图如下
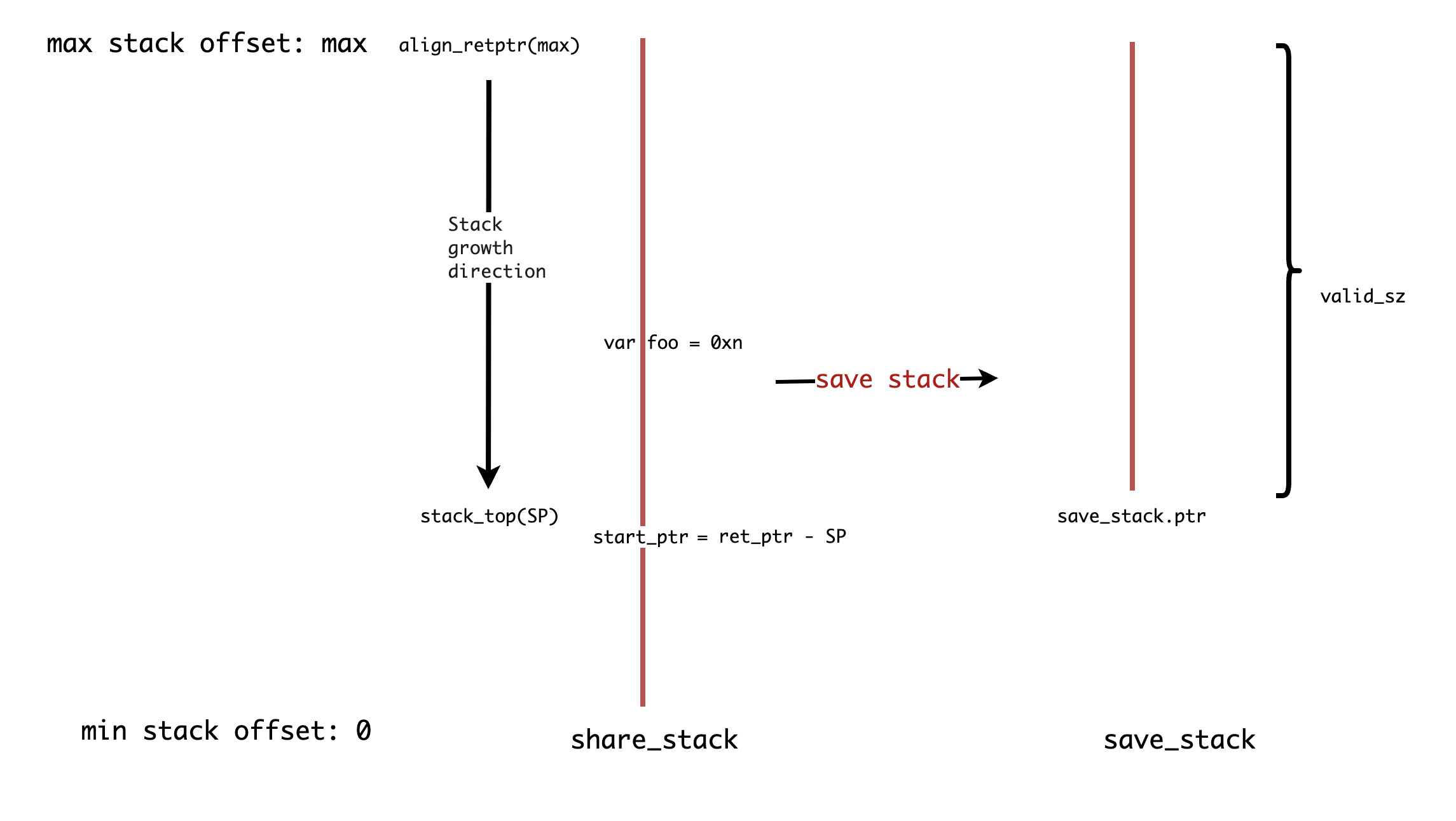
-
在没有 yield 之前, valid_sz 和 SP 都不是固定的值, 所以没法计算出 foo 变量落在 save_stack 上的具体位置!
-
如果 valid_sz 的位置确定 , align_retpt - 0xn 得到的 offset 等于 save_stack.ptr + valid_sz - 0xn 的值。
- 共享栈带来的一个严重的问题,栈指针会随着协程 yield 而无法被其他协程读取,所以 nature 中通过
&q获取的是rawptr<T>类似,一个没有经过验证的 unsafe pointer,通过逃逸分析,或者栈转换也许可以解决这个问题,但 nature 目前都没有实现。如果你可以保证不会发生 coroutine yield 你可以 rawptr,如果不确定,则需要主动将数据在堆中分配。
Runtime GC
runtime/collector.c#runtime_gc
GC (Garbage Collection) 是一种自动内存管理机制,它能够自动识别和回收程序中不再使用的内存空间,从而避免内存泄漏并简化内存管理。GC 一般由三大组件构成
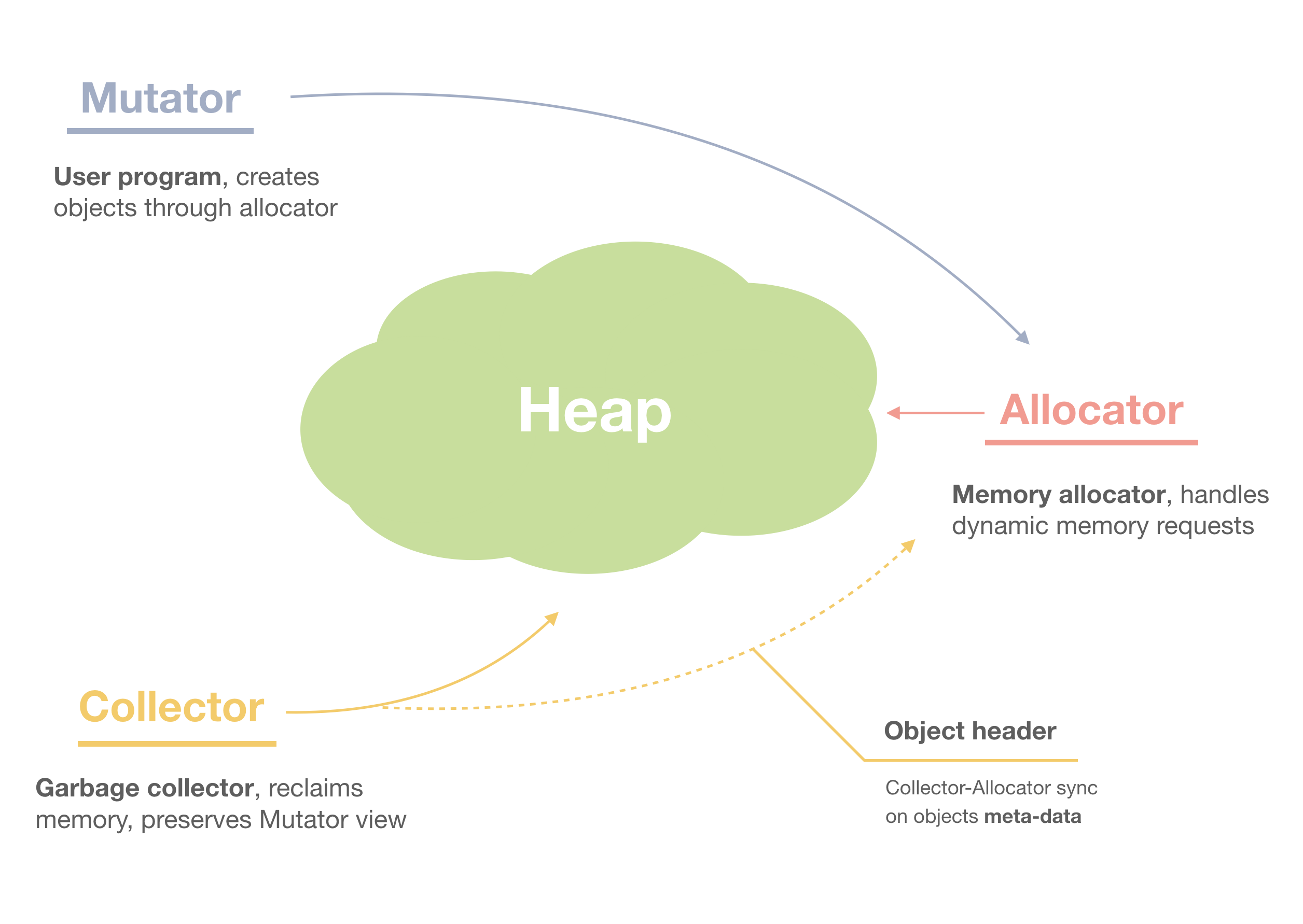
- mutator 也称为用户程序,其在工作过程中会执行三种与堆内存相关相关的操作。
var a = malloc() // New: 从 heap 中申请一片新的内存(obj)分配给局部变量 a
var b = a.foo // Read: 读取 obj a 的 foo 字段赋值给局部变量 b
a.foo = null // Write: 清空 a.foo
b.bar = a.bar // Write: 修改 b.bar 的指向-
allocator 是内存分配器,其向 heap 中申请空闲的内存,申请到的内存我们一般称为 obj,单个 obj 由一个或多个 field 组成。
-
collector 是垃圾收集器,收集并清理用户程序没有使用的 obj。
Nature 编译器使用三色标记(Tri-color marking gc),示例如下
增量与并发 GC
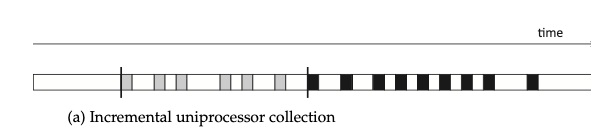
增量垃圾回收通常指在单线程模型下,将 collector 划分成若干子任务,让 mutator(白色块) 和 collector(灰色/黑色块) 交替执行。增量 GC 可以减少用户程序 STW 时间。
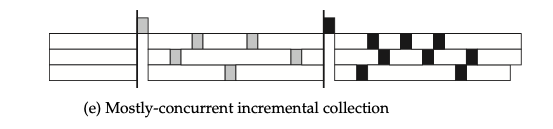
将增量 GC 技术扩展到多核多线程时,可以得到一种在大多数时候都可以并发执行的增量 GC 技术。这也是 golang 和 nature 采取的 GC 方法。
虽然每一个线程都会阻塞 mutaotr, 但是在多线程视角下,总会有一个线程下的用户程序在进行处理。所以在多线程下,我们对 STW(stop the world) 的定义需要进行修改,只有当 collector 会在同一时间阻塞所有的线程时,才能称为 STW。比如上图就有两次 STW。
无论是增量 collector 还是并发 collector, 其主要目的都是最大限度的缩短 mutator 可以感知到的回收停顿时间。在理想情况下并发 collector 也许能和 mutator 完全并行(既不同线程执行自己线程内的回收工作,互不干扰,但是在协程调度模型中,实现起来比较困难),进而缩短整体的执行时间。
而并发回收继续必然要求 mutator 和 collector 之间进行某种程度的通信与同步,其具体表现形式就是 mutator 屏障技术。
屏障技术
上面的增量技术中提到的将 collector 分成若干个子任务与 mutator 交替运行并不能简单的实现,其中最大的问题就是 mutator 会破坏 collector 已经完成的子任务,导致 GC 出现正确性问题。
GC 如果存在正确性问题,将会导致正在使用的内存被错误的回收,产生严重的问题。
而屏障技术则是通过拦截用户程序(mutator) 对 obj 的操作,从而保证 GC 的正确性。上面说过 mutator 在工作过程中会执行三种与堆内存相关的操作。而屏障技术就是拦截其中的 Read 和 Write 操作。
// var b = a.foo // Read: 读取 obj a 的 foo 字段赋值给局部变量 b
var b = read_barrier(a, foo) // 拦截 Read 操作称为读屏障
// a.foo = null // Write: 清空 a.foo
write_barrier(a, foo, null) // 拦截 Write 操作称为写屏障
// b.bar = a.bar // Write: 修改 b.bar 的指向
write_barrier(b, bar, read_barrier(a, bar))lisp 统计过 mutator Read 和 Write 操作,发现读操作的频率远高于写操作,读屏障的开销非常高。所以一般标记-清除垃圾回收通常使用写屏障。
三色标记垃圾回收
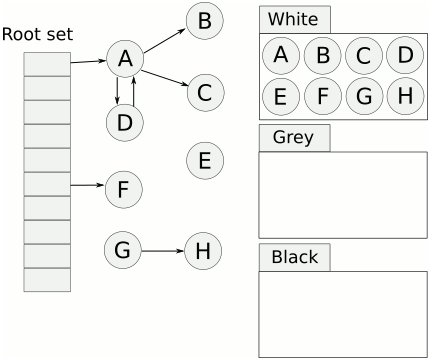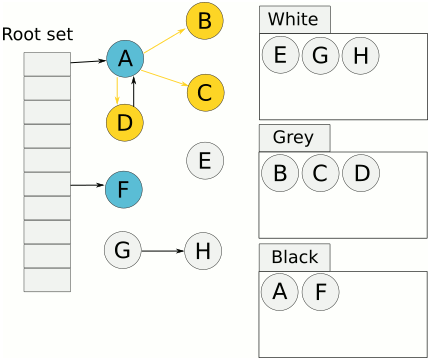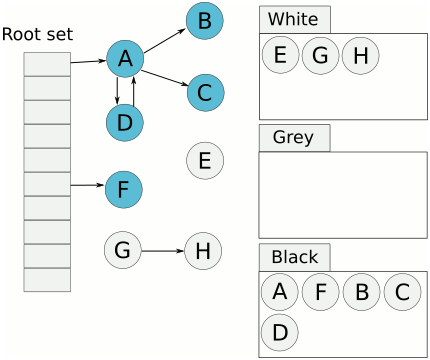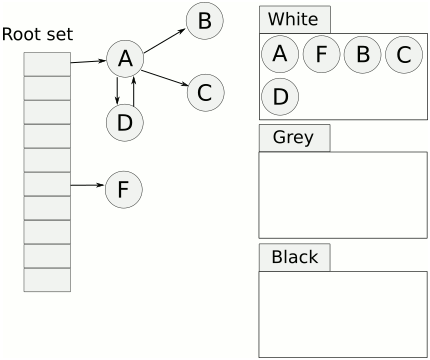
三色标记(Tri-color marking gc) 是一种 标记—清除类型的增量垃圾回收算法。该算法将 GC 中的 obj 分成三种颜色。
- 白色:没有被 collector 扫描过的 obj
- 灰色: 已经被 collector 扫描(加入到 worklist 中) obj,但是 obj 上的 field 还没有被扫描完成
- 黑色: 以及被 collector 扫描,并且 obj 上的 field 都被扫描完成的 obj
上面提到了 worklist,在广度优先遍历中我们一般都会使用这个数据结构,所以三色标记其实就是一个图的广度优先遍历的过程。从 mutator root 出发,遍历所有可达的 obj。没有到达的 obj 就是垃圾需要被清理。
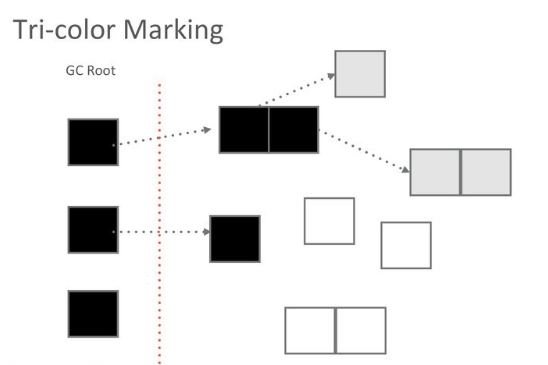
三色标记的增量一般指的是标记阶段。在标记阶段我们可以随时让出当前线程的控制权交给 mutator 执行。
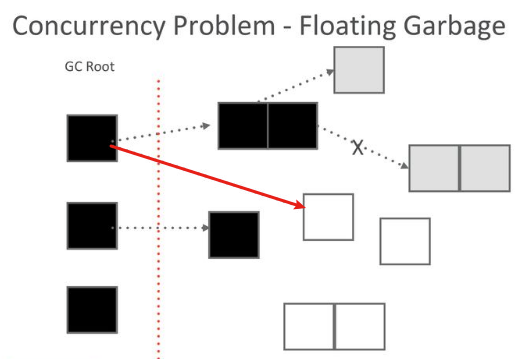
如图,此时线程的控制权交给 mutator,mutator 将一个黑色 obj 指向白色 obj,然后再把线程的控制权交给 collector,此时会发生什么呢?黑色 obj 是已经处理过的 obj, 所以其不会被再次扫描,最终黑色对象指向的白色对象会被当成垃圾错误的清理。
写屏障与三色一致性
三色一致性是一个约定,只要我们遵守这个约定就能保证 obj 被错误的回收。
强三色一致性: 黑色 obj 不能指向白色 obj
弱三色一致性: 黑色 obj 可以指向白色 obj,但是必须存在一个灰色的 obj 指向该 白色 obj
灰色 obj 会被 collector 扫描,所以白色 obj 不会丢失
上面提到的屏障技术可以用来保证三色一致性。屏障技术除了按照读写分类外,还有一种按照 mutator 初始颜色(状态) 进行分类的方式。
在三色标记垃圾回收算法中,当我们在谈论 obj 的颜色时,白色 obj 是还没有被 collector 扫描的 obj,灰色 obj 是已经被 obj 扫描并加入到 worklist 的 obj, 但是 obj.field 还没有被处理。黑色 obj 则是从 worklist 中取出 obj 并对 obj.field 进行处理。
如果我们把 mutator roots 整体作为一个 obj。我们就可以将 mutator 分类为白色/灰色/黑色,这是并发 GC 理论成立的关键。
灰色 mutator 屏障
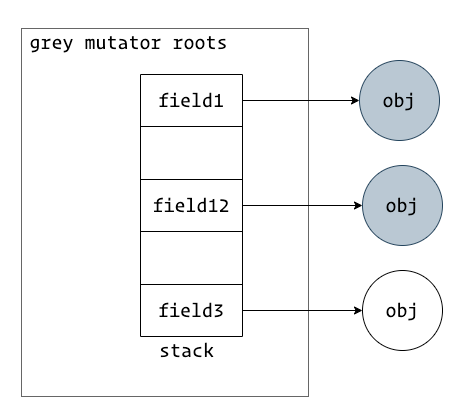
上图是灰色 mutator 存在 field 指向了白色的 obj,此时 mutator roots 必须要被重新扫描才能确保白色 obj 不会被错误的清理。
当我们的 mutator 为灰色时,这意味着存在 root field 指向一个白色的 obj,所以没有必要插入影响性能的读屏障来确保三色一致性。只要通过写屏障确保不会有黑色的 obj 指向白色的 obj 来满足强三色一致性。
var b = a.foo如果需要插入读屏障则是var b = read_barrier(a, foo)
Steele/Boehm/Dijkstra 提出的屏障技术都属于灰色 mutator 屏障,以 Dijkstra 提出的写屏障为例。伪代码如下
atomic write_barrier(obj, field, newobj):
obj->field = newobj
if is_black(obj) // 禁止黑色 obj 指向白色 obj, 满足强三色一致性
shade(newobj)上面的代码表达的东西非常简单,如果 obj 是黑色,则将 newobj 涂成灰色。这样就能满足强三色一致性。
但是随之而来的问题是,由于没有读屏障,在 var b = a.foo 中,如果 a.foo 指向了一个白色的对象。所以在第一次 mark 完成后必须 STW,然后对 mutator roots 进行重新扫描。
黑色 mutator 屏障
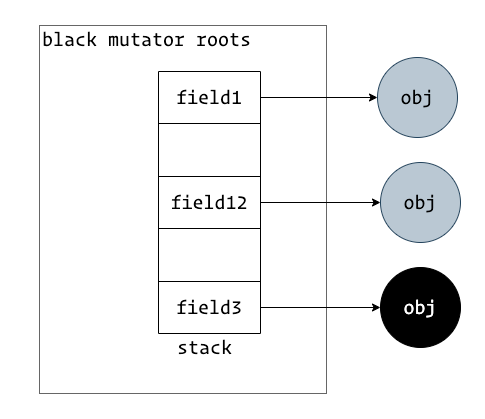
上图是黑色 mutator, 其所有的 field 都已经被处理完成,collector 不需要重新扫描 roots。
黑色 mutator 的所有 root field 都指向了黑色或者灰色 obj,mutator 本身就遵守三色一致性,所以不需要在 mark 完成后进行 STW 重新扫描,但是需要在 GC 开始时进行 STW 扫描 mutator roots。
我们着重讲解一下 Yuasa 提出的基于起始快照(snapshot-at-the-beginning)的删除写屏障技术,这是一种基于黑色 mutator 屏障的技术。
当 mutator roots 扫描完毕,此时 mutator 处于黑色状态,在所有线程开启写屏障。写屏障伪代码如下
atomic write_barrier(obj, field, newobj):
oldobj = obj
// obj->field 指向的 oldobj 是白色的,则在更新 obj->field 前将 oldobj 涂成灰色
// 灰色就是 mark 并且放到 worklist 中,等待 collector 处理
if is_white(oldobj)
shade(oldobj)
obj->field = newobj 在 obj->field = newobj 的过程中,如果 obj 是黑色的,则会产生黑色 obj 指向白色的 newobj,在这一阶段,yuasa 算法不会进行任何处理,只有当 obj->filed 指向的 oldobj 被覆盖时,yuasa 算法才会产生作用将 oldobj 涂抹成灰色,让 collector 能够重新处理该 obj。
在 Yuasa 快照算法中,
oldobj = obj->filed。这里的 oldobj 就是快照。
yuasa 算法不需要 read_barrier,不需要 rescan stack,并且允许 mutator 指向一个白色 obj。但是依旧满足弱三色一致性
因为在 mark 阶段,newobj 如果被 mutators root 引用,这个 newobj 一定被其他对象引用。一个 newobj 不可能在 GC mark 阶段凭空出现被 root 引用。除非在 GC 开始之前这个 newobj 已经被其他对象引用。
var a = allocate() // 这是一个全新的对象,gc 开始后 allocate 会进行主动标记,所以不需要考虑
var b = a.foo a.foo 指向的 obj 即使是白色也没有关系,因为 a 指向的 obj 一定是灰色或者黑色。
混合写屏障
golang 在 1.8 版本实现了基于 Dijkstra + Yuasa 的混合写屏障,nature 也同样采取了这样的方式。基于混合写屏障,我们可以实现非常短暂的 STW 的并发 GC。
混合写屏障继承了两者的最优属性,运行在 mark 开始阶段并发扫描 root,并且在 mark 结束后保证 root 为黑色。
atomic write_barrier(obj, field, newobj):
if is_white(obj->field)
shade(obj->field) // grey
// stack 扫描完成后退化成黑色写屏障
if stack is grey:
shade(newobj) // grey
obj->field = newobj
// 形式 2,代码含义都是一致的
atomic write_barrier(slot, ptr):
shade(*slot) // yuasa
if current stack is grey:
shade(ptr) // Dijkstra 写屏障
*slot = ptr // 实际写入在 GC mark 开始之前需要进行一个短暂的 STW 开启全局写屏障,一旦写屏障开启,则可以多线程并发的进行 roots 的扫描,按照上面的代码,如果当前 gorouine 还没有被挂起扫描,则当前 gorouine 中的所有的指针写入操作对应的新的 obj 都会被标记为灰色。 一旦当前 gorouine 被挂起(本质上就是 goroutine 维度的短暂的 STW)扫描完成,则写屏障退化为删除写屏障。一旦写屏障开启,所有新分配的对象都会黑色。
因此即使不同的颜色 gorouine 操作同一个 obj,也能确保遵循弱三色一致性。
STW 阶段
不同的屏障技术所要求的 STW 阶段各不相同
- 灰色 mutator 需要在 mark 开始之前需要 STW 所有线程开启写屏障,否则如果部分线程开启了写屏障部分线程没有开启写屏障。则未开启写屏障的线程如果操作了 obj 可能会让黑色的
obj->field唯一指向白色的 obj 从而导致违反三色一致性。
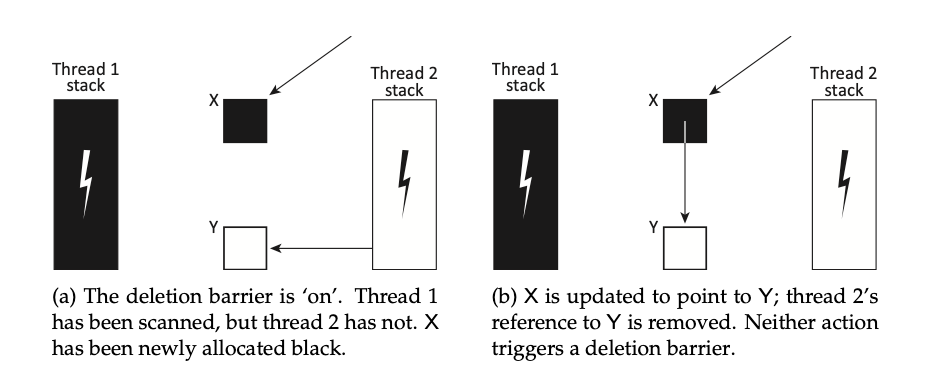
-
灰色 mutator 在 mark 结束之前还需要进行一次 STW 对 root 进行重新扫描。
-
黑色 mutator 需要在 mark 开始之前 STW 扫描 root 然后开启写屏障。
-
混合写屏障则只需要在 mark 开始之前 STW 开启写屏障即可,后续的 mark 都是多线程并发的。
nature 虽然采用了混合写屏障,但是还是需要两个阶段 STW,当然这两个阶段的 STW 耗时非常短。
Runtime Allocator
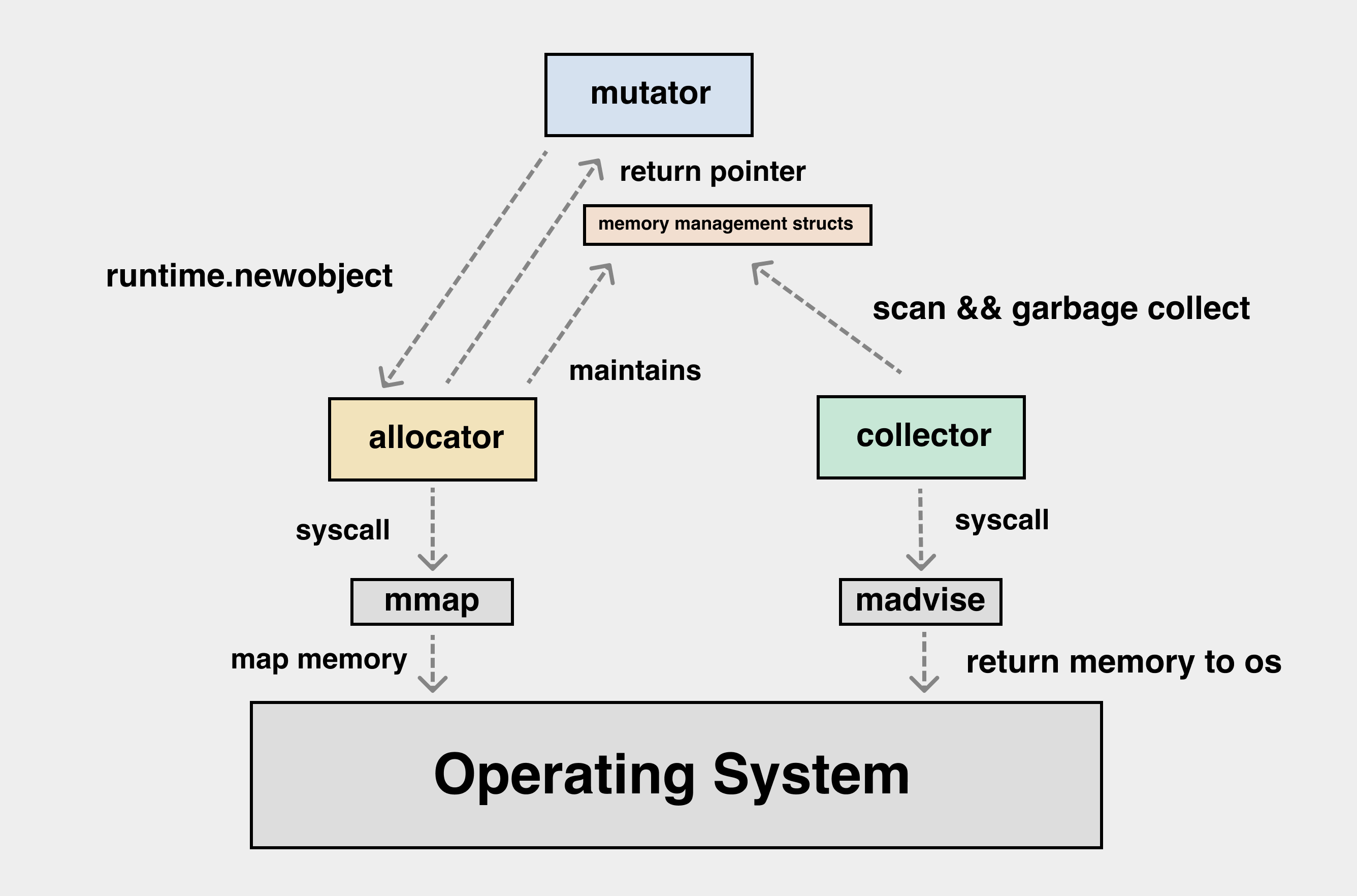
runtime/allocator.c#rti_gc_malloc
allocator 组件负责向操作系统申请内存, nature 的内存分配器直接参考 golang 实现,并进行了一定的简化。结构如图
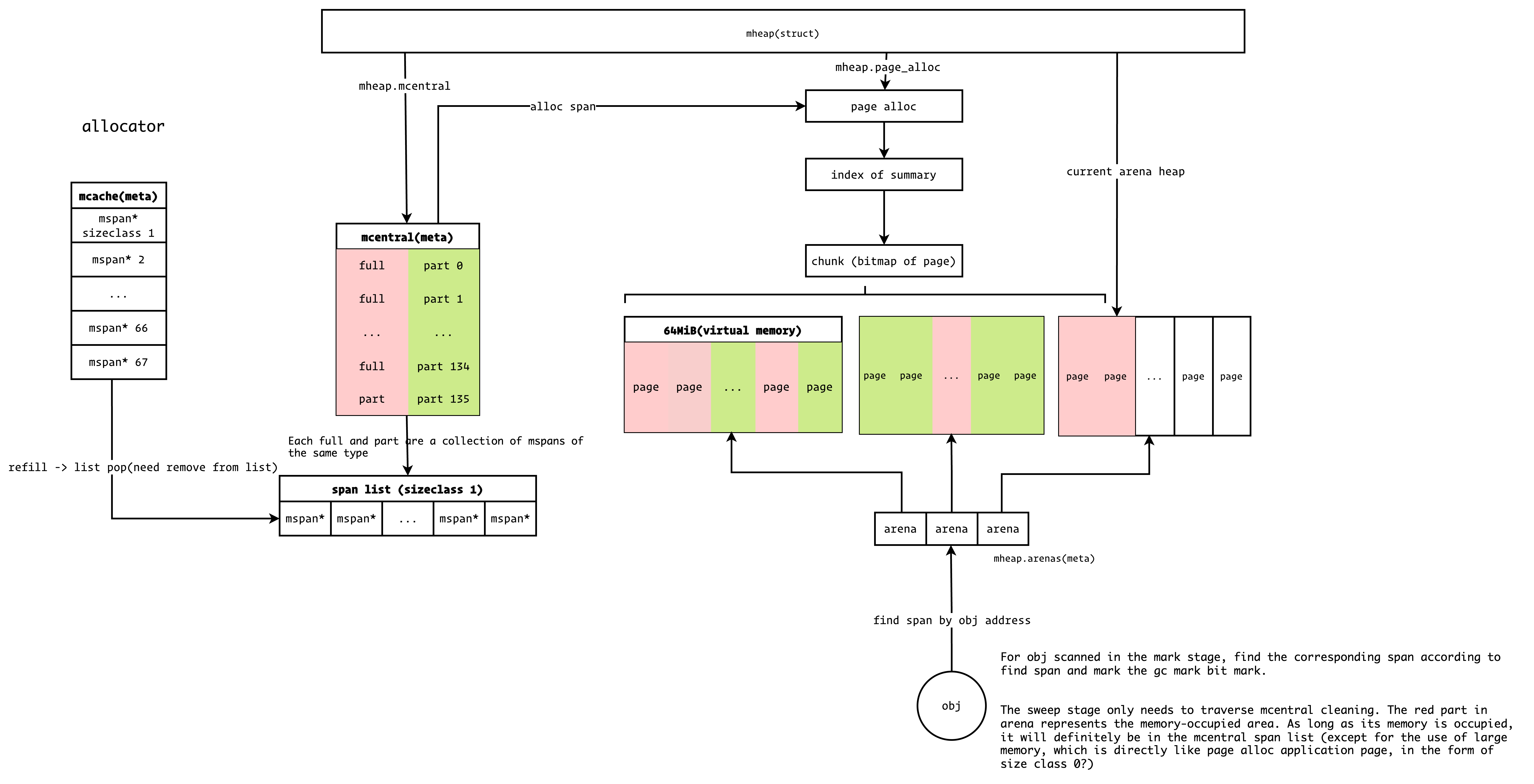
在底层,nature 使用 mmap 函数向操作系统申请内存,collector 完成后通过 madvise 函数将内存归还给操作系统。
Runtime Libuv
libuv 是一个跨平台的异步 I/O 库,nature 使用 libuv 处理网络 IO。
在 runtime 实现中,为每一个 share processor (cpu count)创建了一个 event loop 用来处理异步 I/O 事件。但是由于 libuv 不是线程安全的,这与协程的思想是冲突的,所以在使用 libuv 的时候需要注意,避免跨 share processor 使用 libuv event_loop。
以 http server 服务器为例子,详细代码参见 runtime/nutils/http.c
- IO 事件由 main libuv loop 监听和触发(如 TCP 连接、数据读写等)
- 当 IO 事件就绪时,创建新的协程处理业务逻辑
- 业务逻辑处理完毕后,必须将相关数据通过 uv_async 发送回原始 libuv loop 执行实际的 IO 操作,而不是直接在当前协程所属的 share processor 的 event loop 处理 IO 操作
Runtime Reflect
utils/custom_links.h
运行时依赖编译时的一些数据来实现错误追踪,类型反射,GC 栈扫描等功能。custom_links.h/type.h 中注册了需要共享到运行时的数据类型。
- symdef_t : 定义了符号的结构,包含基地址、大小、GC标记等信息
- fndef_t : 定义了函数的结构,包含函数的基地址、大小、运行时信息、栈信息等
- caller_t : 定义了调用者的结构,记录调用位置、行列号等信息
- rtype_t : 定义在 utils/type.h,定义了类型的反射信息,包括 size/hash/gc_bits/kind 等数据信息
在编译时将这些数据收集完成后,将这些数据序列化到 object 文件并在 ELF/Mach-O 符号表注册相关的符号绑定。
src/build/build.c#elf_custom_links src/build/build.c#mach_custom_links
接下来需要在 runtime 中只需要声明 extern 符号即可读取相关数据。